Publications
2022
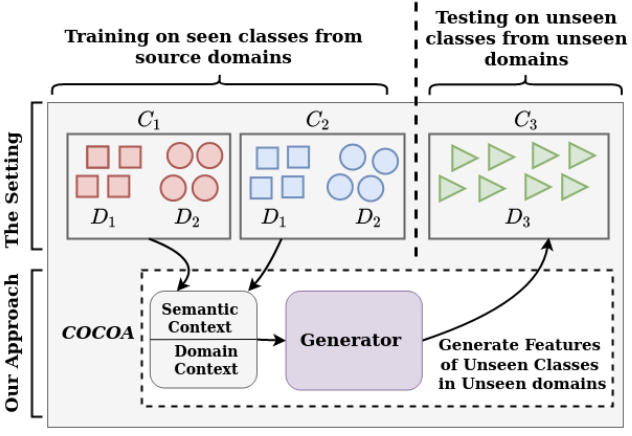
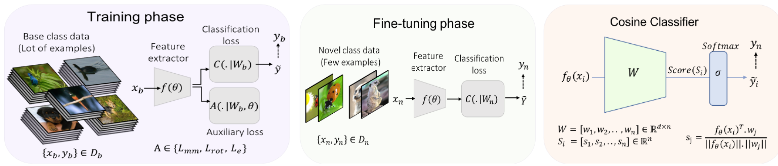
COCOA: Context-Conditional Adaptation for Recognizing Unseen Classes in Unseen Domains [Abs] [Poster] [PPT]
Puneet Mangla, Shivam Chandhok, Vineeth N Balasubramanian, Fahad Shahbaz Khan
Published in Proceedings of IEEE Winter Conference on Applications of Computer Vision (WACV) 2022
(Also presented at IJCAI 2021 Weakly Supervised Representation Learning Workshop)
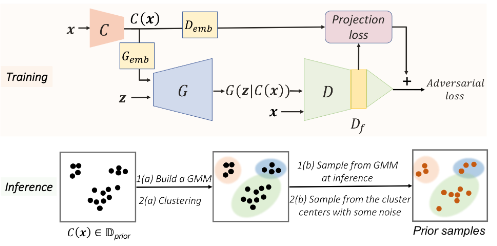
Data InStance Prior (DISP) in Generative Adversarial Networks [Abs] [Poster] [PPT]
Puneet Mangla, Nupur Kumari, Mayank Singh, Vineeth N Balasubramanian, Balaji Krishnamurthy
Published in Proceedings of IEEE Winter Conference on Applications of Computer Vision (WACV) 2022
2021
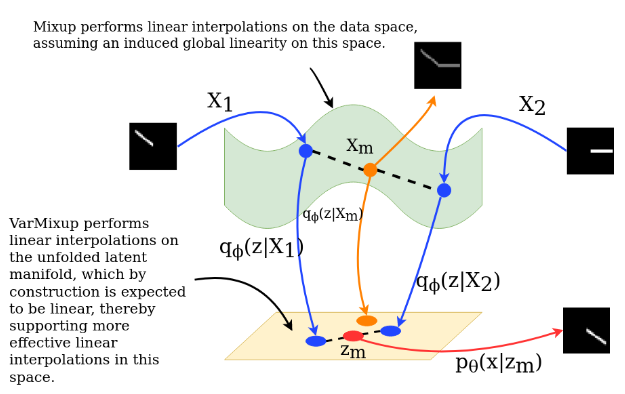
On the Benefits of Defining Vicinal Distributions in Latent Space [Abs] [Poster] [PPT]
Puneet Mangla, Vedant Singh, Shreyas Jayant Havaldar, Vineeth N Balasubramanian
Extended version accepted at Elsevier Journal - Pattern Recognition Letters (Impact Factor: 3.756)
Best Paper Award at Workshop on Adversarial Machine Learning, CVPR 2021
(Also accepted at RobustML Workshop, ICLR 2021 (Oral) and Generalization Workshop, ICLR 2021)
2020
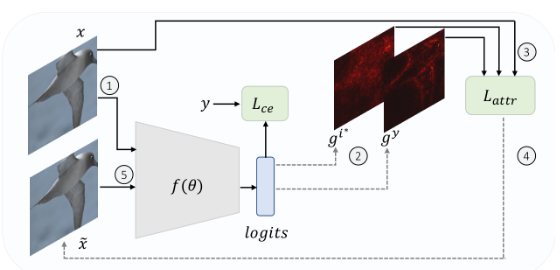
Attributional Robustness Training using Input-Gradient Spatial Alignment [Abs] [PPT]
Mayank Singh, Nupur Kumari, Puneet Mangla, Abhishek Sinha, Vineeth N Balasubramanian, Balaji Krishnamurthy
Published in Proceedings of European Conference on Computer Vision (ECCV) 2020
On Saliency Maps and Adversarial Robustness [Abs] [PPT]
Puneet Mangla, Vedant Singh, Vineeth N Balasubramanian
Published in Proceedings of European Conference of Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD) 2020
Charting the Right Manifold: Manifold Mixup for Few-shot Learning [Abs] [Poster]
Puneet Mangla, Mayank Singh, Abhishek Sinha, Nupur Kumari, Vineeth N Balasubramanian, Balaji Krishnamurthy
Published in Proceedings of IEEE Winter Conference on Applications of Computer Vision (WACV) 2020
(Also accepted as spotlight at NeurIPS 2020 - MetaLearn Workshop)
2019
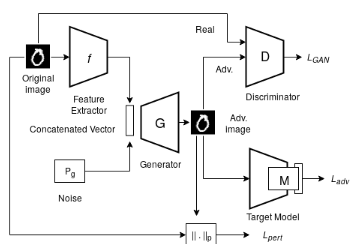
AdvGAN++ : Harnessing latent layers for adversary generation [Abs]
Puneet Mangla, Surgan Jandial, Sakshi Varshney, Vineeth N Balasubramanian
Published in Proceedings of Neural Architects Workshop, ICCV 2019